📌 Overview
The NBA Data Lake Pipeline project automates the process of collecting, storing, and analyzing NBA player data using AWS. This pipeline fetches data from the Sportsdata.io API and sets up a data lake that is easily queryable via AWS Athena. To enhance automation, GitHub Actions are used to deploy the pipeline, while AWS CloudWatch logs all activities.
What This Project Does
- Data Fetching: Retrieves NBA player data from the Sportsdata.io API.
- Data Storage: Saves fetched data in an AWS S3 bucket under the
raw-data/folder. - Data Cataloging: Creates an AWS Glue database and table (
nba_players) to manage data schemas. - Querying: Configures AWS Athena to enable SQL queries on the data.
- Automation: Utilizes GitHub Actions to trigger the entire pipeline on every push.
- Logging: Uses AWS CloudWatch for tracking and troubleshooting pipeline operations.
Prerequisites
- AWS Account: An active AWS account.
- AWS Permissions: Ensure your IAM role or user has the following permissions:
- S3:
s3:CreateBucket,s3:PutObject,s3:DeleteBucket,s3:ListBucket - Glue:
glue:CreateDatabase,glue:CreateTable,glue:DeleteDatabase,glue:DeleteTable - Athena:
athena:StartQueryExecution,athena:GetQueryResults
- S3:
- Sportsdata.io API Key: A valid API key from Sportsdata.io.
Setup & Installation
- Clone the Repository:
git clone https://github.com/kingdave4/Nba_Data_Lake.git cd Nba_Data_Lake
GitHub Secrets
Configure the following secrets in your GitHub repository settings (Settings > Secrets and variables > Actions):
- AWS_ACCESS_KEY_ID: Your AWS access key.
- AWS_SECRET_ACCESS_KEY: Your AWS secret access key.
- AWS_REGION: The AWS region (e.g.,
us-east-1). - AWS_BUCKET_NAME: Your designated S3 bucket name.
- NBA_ENDPOINT: The Sportsdata.io API endpoint.
- SPORTS_DATA_API_KEY: Your Sportsdata.io API key.
Pipeline Workflow
The pipeline follows these sequential steps:
- S3 Bucket Creation: Creates an S3 bucket (if it doesn’t already exist) to store the raw JSON data.
- Glue Database Setup: Creates a new AWS Glue database to manage the data schema.
- Data Fetching: Executes the Python script to fetch NBA player data from the Sportsdata.io API.
- Data Conversion: Converts the fetched data to JSON format.
- Data Upload: Uploads the JSON data to the S3 bucket under the raw-data/ folder.
- Glue Table Creation: Creates a Glue table named nba_players to catalog the NBA player data.
- Athena Configuration: Sets up AWS Athena to enable SQL queries on the stored data.
GitHub Actions Workflow
The automation is handled via a GitHub Actions workflow defined in .github/workflows/deploy.yml. This workflow:
Sets up the necessary AWS resources. Executes the Python script (nba_data_script.py) to run the pipeline. Logs the entire process to AWS CloudWatch. Triggers automatically on every push to the repository. name: Deploy NBA Data Lake Pipeline
on:
push:
branches:
- main # Trigger on push to the main branch
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Python script
run: |
# Set AWS credentials from GitHub Secrets
aws configure set aws_access_key_id ${{ secrets.AWS_ACCESS_KEY_ID }}
aws configure set aws_secret_access_key ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws configure set region ${{ secrets.AWS_REGION }}
# Execute the data pipeline script
python python_script/nba_data_script.py
env:
AWS_BUCKET_NAME: ${{ secrets.AWS_BUCKET_NAME }}
NBA_ENDPOINT: ${{ secrets.NBA_ENDPOINT }}
SPORTS_DATA_API_KEY: ${{ secrets.SPORTS_DATA_API_KEY }}
Usage
After a successful pipeline execution, you can:
Query the Data: Use AWS Athena to execute SQL queries. For example:
SELECT FirstName, LastName, Position, Team FROM nba_players WHERE Position = 'SG';
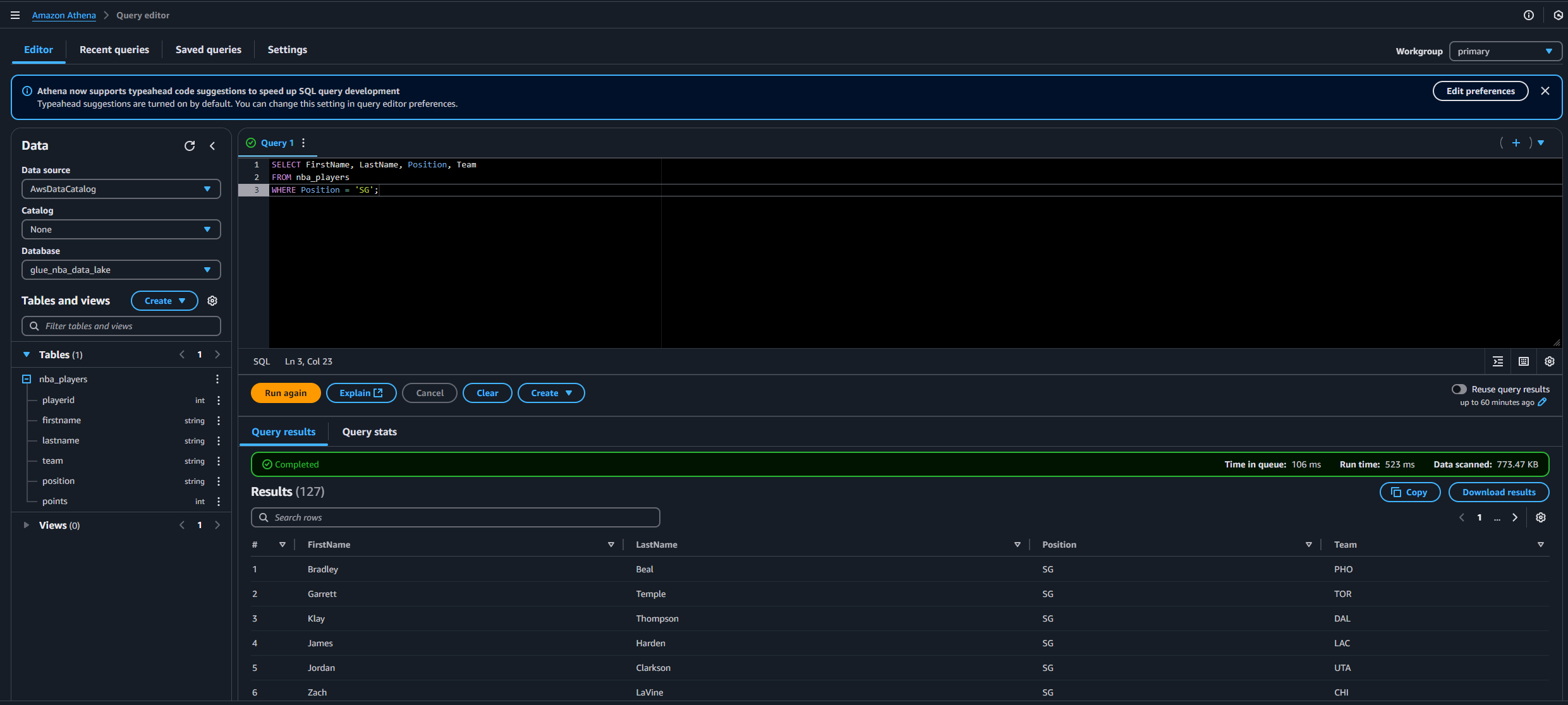
Monitor Logs: Check AWS CloudWatch for detailed logs and troubleshooting information.
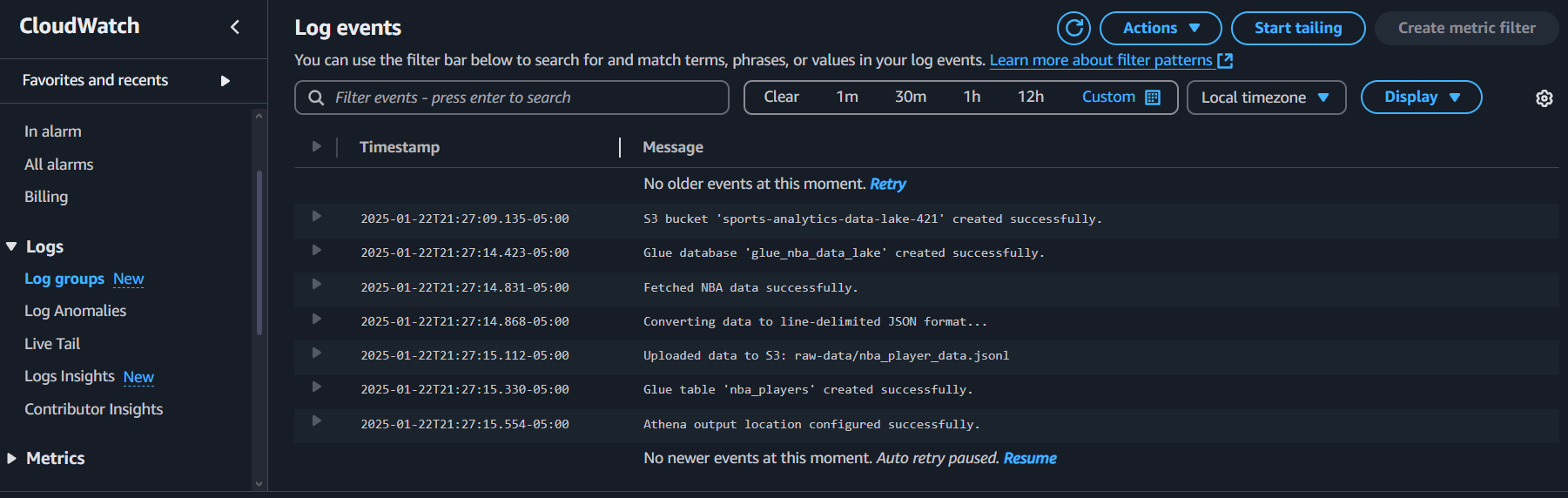
Troubleshooting
- API Key/Secrets Missing: Ensure that all required GitHub Secrets are correctly configured.
- AWS Permission Issues: Verify that your AWS IAM role or user has the necessary permissions.
- GitHub Actions Errors: Review the logs in the GitHub Actions tab for any errors during deployment.
- API Rate Limits: If data fetching fails, confirm that you are not exceeding the Sportsdata.io API rate limits.
What I Learned
- Leveraging AWS services (S3, Glue, Athena, CloudWatch) to build a scalable data lake.
- Automating deployments using GitHub Actions.
- Securing sensitive credentials using GitHub Secrets.
- Processing and analyzing real-world NBA data using Python.
- Implementing effective logging and monitoring practices for troubleshooting.
Future Enhancements
- Automated Data Ingestion: Integrate AWS Lambda to schedule and trigger the pipeline automatically.
- Data Transformation: Implement an AWS Glue ETL job to transform and clean the data.
- Advanced Analytics: Integrate AWS QuickSight for enhanced visualizations and insights.
📁 Repository
GitHub - kingdave4/AzureDataLake
📬 Contact
For questions, feedback, or opportunities, feel free to connect on LinkedIn or drop me a message through the contact form.