🚀 Introduction
Welcome to my third project in the DevOps Challenge! This time, I tackled the automation of collecting, storing, and analyzing NBA player data using AWS services. My goal was to fetch real-time NBA data from the Sportsdata.io API and create a scalable data lake on AWS. To take it a step further, I automated the entire workflow using GitHub Actions and set up AWS CloudWatch for logging and monitoring.
🏀 What This Project Does
This project automates the process of collecting NBA player data and storing it in an AWS data lake. Here’s what it accomplishes:
Fetch NBA Data – Retrieves player stats from the Sportsdata.io API.
Store Data in S3 – Saves the fetched data in AWS S3 in JSON format.
Create a Data Lake – Uses AWS Glue to structure and catalog the data.
Enable SQL Queries – Configures AWS Athena to query the data using SQL .
Log Everything – Implements AWS CloudWatch for logging and tracking all activities.
🛠️ Tools and Technologies Used
To build this pipeline, I leveraged the following technologies:
Programming Language: Python 3.8
AWS Services: S3, Glue, Athena, CloudWatch
API Provider: Sportsdata.io (NBA Data API)
Automation: GitHub Actions
📝 Setup Instructions
Step 1: Prerequisites
Before setting up this project, ensure you have:
An AWS account.
A Sportsdata.io API key.
The necessary IAM role/permissions in AWS for:
S3:
s3:CreateBucket,s3:PutObject,s3:ListBucketGlue:
glue:CreateDatabase,glue:CreateTableAthena:
athena:StartQueryExecution,athena:GetQueryResults
Add these secrets to your GitHub repository (Settings > Secrets and variables > Actions):
| Secret Name | Description |
|----------------------|----------------------------------|
| AWS_ACCESS_KEY_ID | AWS access key |
| AWS_SECRET_ACCESS_KEY | AWS secret access key |
| AWS_REGION | AWS region (e.g., `us-east-1`) |
| AWS_BUCKET_NAME | Your S3 bucket name |
| NBA_ENDPOINT | Sportsdata.io API endpoint |
| SPORTS_DATA_API_KEY | Sportsdata.io API key |
Step 2: How It Works
Clone the Repository
git clone https://github.com/kingdave4/Nba_Data_Lake.git cd nba-data-lake-pipelineProject Breakdown
The project is structured to run a Python script within a GitHub Actions workflow.
The workflow YAML file (
.github/workflows/deploy.yml) automates the execution of the script.The Python script handles:
AWS service configuration and initialization
Fetching and processing NBA data
Uploading data to S3 and cataloging it with Glue
Enabling Athena queries for analysis
🏗️ Order of Execution
Here’s how the Python script executes step by step:
Create an S3 Bucket – The bucket is used to store raw NBA data.
Create a Glue Database – Organizes and catalogs the data.
Fetch NBA Data – Calls the Sportsdata.io API for player data.
Convert Data to JSON Format – Ensures compatibility with AWS services.
Upload Data to S3 – Stores the JSON files in a structured folder.
Create a Glue Table (
nba_players) – Allows querying via Athena.Enable Athena for SQL Queries – Set up SQL-based analytics on the dataset.
⚙️ GitHub Actions: Automating the Deployment
The GitHub Actions workflow is set up to trigger on every push to the repository. When executed, it:
Installs dependencies
Sets up AWS credentials
Runs the Python script to fetch and store NBA data
Configures AWS services automatically
This ensures that each code update automatically refreshes the pipeline, making it hands-free!
📊 Results of the Pipeline Execution
Once the pipeline runs successfully:
- S3 Bucket: Stores all raw data in the
raw-data/folder. - AWS Glue: Manages the data schema.
- AWS Athena: Enables querying of the data using SQL.
Example SQL Query (Athena)
SELECT FirstName, LastName, Position, Team
FROM nba_players
WHERE Position = 'SG';
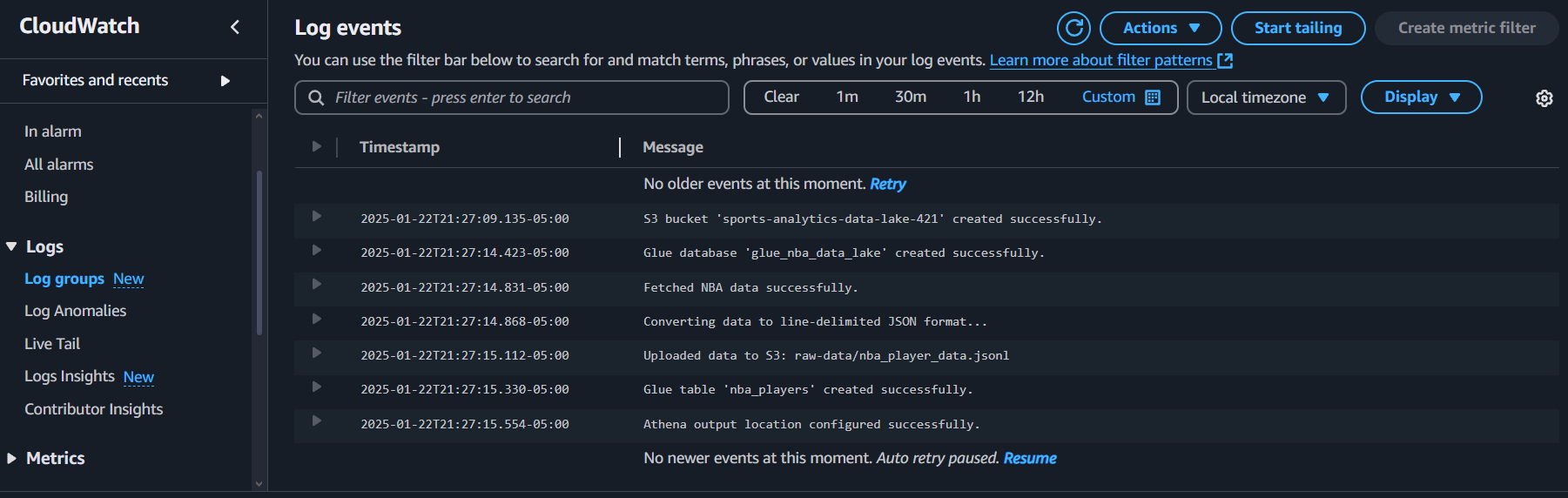
🛡️ Error Tracking & Logging with CloudWatch
To ensure smooth execution, I integrated AWS CloudWatch Logs to track key activities, including:
- API calls
- Data uploads to S3
- Glue catalog updates
- Athena query executions
If an error occurs (e.g., missing API keys or AWS permissions), CloudWatch provides insights for troubleshooting.
🌟 Lessons Learned
This project reinforced several key DevOps and cloud computing concepts:
✅ Leveraging AWS services (S3, Glue, Athena, CloudWatch) to build scalable data pipelines.
✅ Automating workflows using GitHub Actions.
✅ Securing credentials and sensitive data using GitHub Secrets and .env files.
✅ Fetching and processing real-world data from an API.
✅ Using SQL with AWS Athena for data analysis.
✅ Implementing logging and monitoring with CloudWatch.
🔮 Future Enhancements
To improve the pipeline further, I plan to:
✨ Automate data ingestion with AWS Lambda – Run the pipeline on a scheduled basis.
✨ Implement a data transformation layer with AWS Glue ETL – Clean and enrich the data.
✨ Add advanced analytics and visualizations using AWS QuickSight – Create dashboards for insights.
🎯 Final Thoughts
This project was an exciting challenge that combined DevOps, cloud computing, and data engineering.
Automating data collection and analysis using AWS tools has been a game-changer for me.
I’m eager to keep building and refining my skills in cloud automation and data engineering!