🚀 My Azure Data Lake Deployment & Refresh Journey
When I made the career shift from IT Support to Cloud Engineering, I understood I would require a hands-on project incorporating infrastructure-as-code, serverless compute, and analytics. I decided to automate a real-world application processing live NBA data into an Azure Data Lake, updating it at a scheduled time, and allowing rapid querying with Synapse. Through it, I learned not only APIs and Terraform; I learned the significance of automation and observability in production systems.
🌟 Why This Project Was Important to Me
In the early days of my transition, I was frequently reading docs but having trouble understanding how things fit together in a live system. This project provided me with end-to-end visibility:
- Terraform introduced me to repeatable, versioned infrastructure.
- Azure Functions introduced me to the potential of serverless patterns and managed identities.
- Synapse Analytics unveiled the process of how raw information becomes insights.
When I saw my first JSON file appear in Blob Storage automatically every ten minutes, I felt a rush of confidence this was the sort of cloud engineering I wanted to do as a career.
🏗️ High-Level Architecture
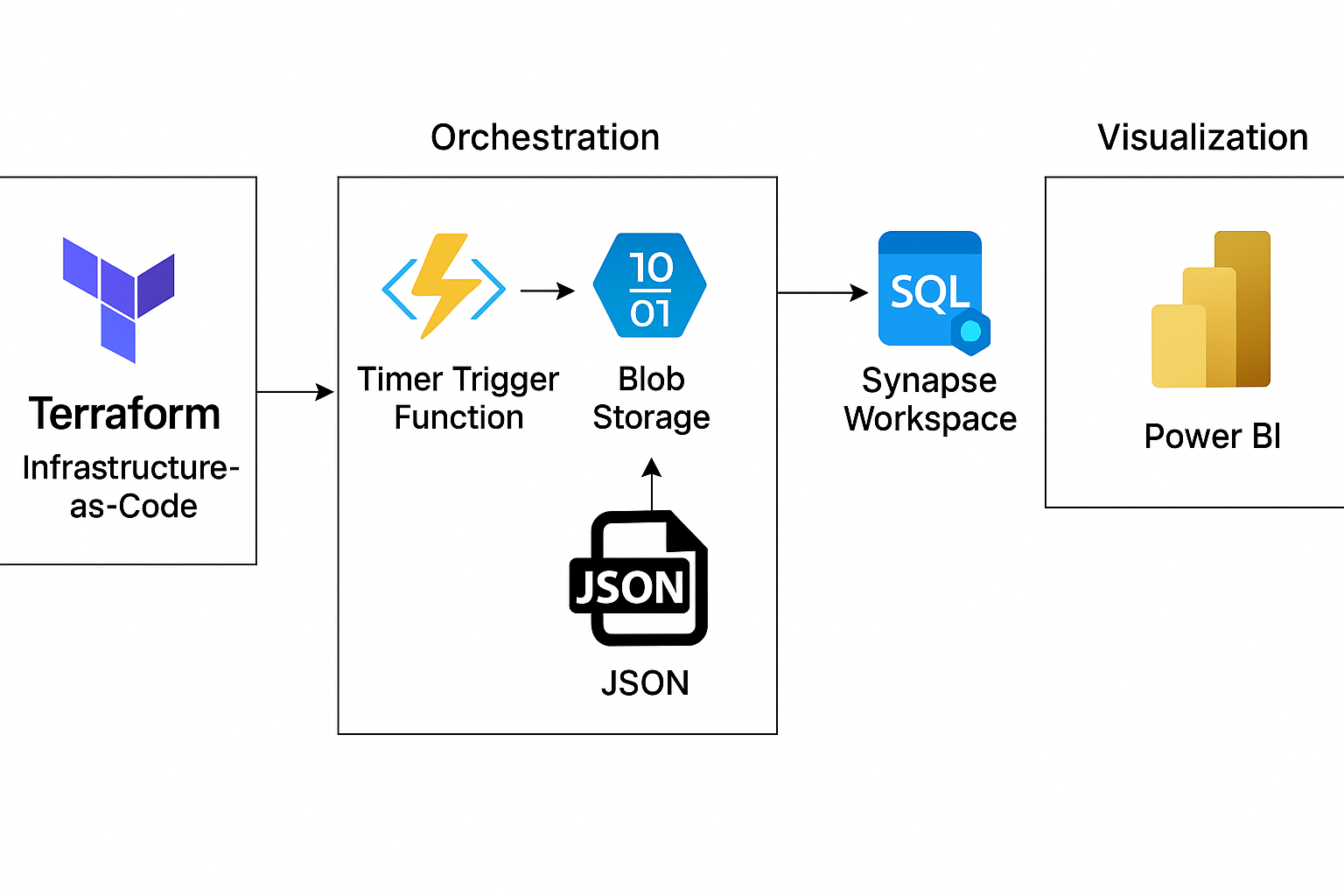
Automated data flow: Terraform → Azure Function → Data Lake → Synapse
- Terraform: One source of truth for all Azure resources (Resource Group, Storage, Gen2, Synapse, Key Vault, Function App, Monitor).
- Azure Function (Python): A timer triggered every 10 minutes to retrieve the latest NBA statistics and publish them to Blob Storage.
- Azure Synapse: Serverless SQL pools to browse the ingested JSONL data rather than provisioning servers.
- Observability: Application Insights and Log Analytics make it possible for me to detect any failure or performance issues immediately.
🔧 Behind the Scenes: Tools & Tips
I relied heavily on the Azure SDK for Python and the AzureRM Terraform provider. The following were the lessons learned:
- Securing Secrets: I didn’t hard-code the keys, rather stored all of them in Key Vault and accessed them securely in my Function App using
DefaultAzureCredential. - Modular Terraform: Dividing resources into modules made it possible to reuse configurations and made it simpler to comprehend the outputs of
terraform plan. - Local Debugging: Locally running the function using mock secrets enabled rapid iteration prior to publishing to Azure.
I left most of the code samples in the repository please feel free to go through main.tf, variables.tf, and the Python files if you prefer to see complete samples.
🎓 Lessons Learned & Challenges Overcome
- First Deploy Hiccups: A simple mistake I made during my first Terraform deploy was to forget to grant the managed identity the right role assignments on Key Vault.
Lesson: Double‑check role assignments! - Networking Gotchas: The firewall rules in Synapse caught me off guard until I understood I had to whitelist my client IP on the Synapse workspace settings.
- Scheduling Balance: A 10-minute trigger was responsive, but I adjusted the timer after seeing minor throttling on the Sportsdata.io API.
Each hurdle compelled me to delve deeper into Azure documentation and sharpened my debugging instincts.
🚀 What’s Next on My Roadmap?
- Orchestration: I’m investigating using Azure Data Factory to orchestrate several different data sets (e.g., weather, stock information) with NBA statistics.
- Visualization: Directly linking Power BI to Synapse to create automatically refreshing dashboards from which I don’t need to initiate queries.
- CI/CD: Converting my Terraform and Function deployments to an Azure DevOps pipeline, where each merge deploys the entire environment.